Section 8 Principal Component Analysis (PCA)
Under this menu, you can obtain a global overview of a dataset to visually identify groups, trends or outliers.
- Numerical output: percentage and cumulative percentage of variance explained for each component
- Graphical outputs: screeplot, projection of individuals, projection of variables on circle of correlation
- Extract a new dataset with reduced dimensions based on principal components (PCs).
The method used in ASTERICS comes from the package FactoMineR (Lê, Josse, and Husson 2008).
For further information on PCA and FAMD (in French):
http://factominer.free.fr/factomethods/analyse-en-composantes-principales.html
Pagès Jérôme (2002). “Analyse factorielle de données mixtes” (PDF). Revue de Statistique appliquée. 52 (4): 93–111. (Pagès 2004)
8.1 Run PCA
How to set options?
The analysis performed in this workflow is “Factorial Analysis of Mixed Data (FAMD),” which is a generalization of PCA to the cases where categorical variables are present in the dataset.
- when your dataset contains only numeric variables, this analysis is identical to PCA;
- when your dataset contains numeric and categorical variables, you can use the option “Force PCA” to discard categorical variables and perform a PCA.
Important note: PCA is performed with raw values (data are not scaled to unit variance before they are processed). If you want to perform scaled PCA, go to the menu “Edit / Dataset edition” and scale your dataset before PCA.

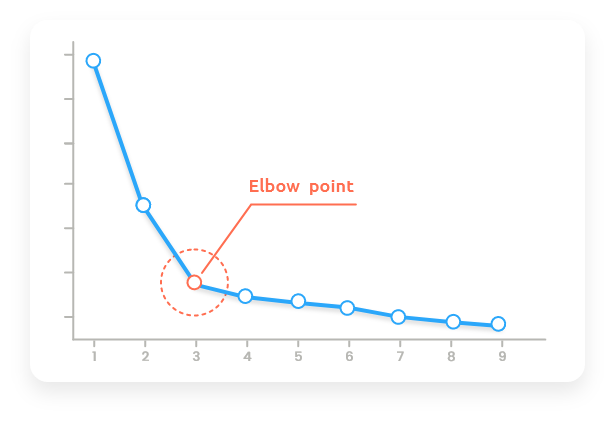
Percentage of explained variance reproduced in your PCA must be as large as possible to ensure what you see is a main trend of your dataset. Use the elbow rule (screegraph) and try to keep at least 80% of cumulative explained variance when you choose a number of principal components (PCs).
8.2 Explore individuals


Combine the plot of individuals with colors (or shapes / sizes) giving information on other variables (e.g., variables of your design) to check if colors are organized with respect to PCs. This would mean that the main variability of your dataset are also associated to the variable that has been used to color individuals in your plot.
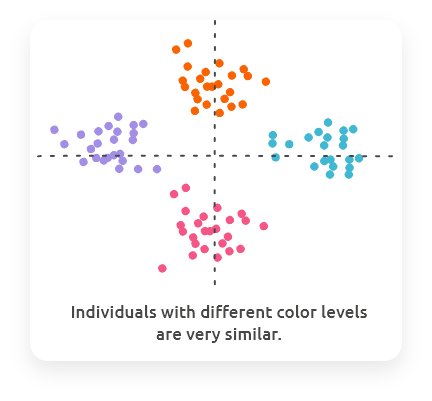
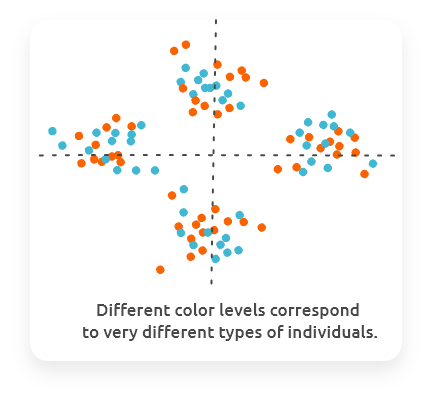
8.3 Explore variables
How to set options?
By choosing a correlation threshold, only variables with a correlation larger than this number are displayed on the plot (to make it easier to read).
8.3.1 Interpret axes

Only variables well correlated with axes can be interpreted. Select a correlation threshold to display the most correlated variables.
8.3.2 Case of categorical variables
For FAMD (PCA with categorical variables), the levels of the categorical
variables are displayed in a space which scale is not comparable to the correlation
plot of numerical variables.
You can explore them on an additional plot.
Distances in this space are interpreted in terms of common co-occurrence of
the two levels among individuals (the closer the two levels on the plot, the
higher the co-occurrence of these levels).
Only levels of categorical variables for which the reproduced correlation ratio
is larger than the chosen threshold are displayed.
8.4 Extract new data
How to set options?
Set options in left panel to generate a new dataset from the analysis:
with the criterion “Components, by number,” the first components (number to be specified by the user) will be extracted and used as a new dataset;
with the criterion “Components, by explained variance” (when available), the first components (number automatically set to reach the targeted percentage of explained variance or a targeted correlation ratio for categorical variables) will be extracted and used as a new dataset;
with the criterion “Variables,” the variables the most correlated with the first components will be selected and used as a new dataset.
When the dataset is extracted, you can use it in other analyses or check it in menu “My workspace.”
8.5 Default parameters
Used function and default parameters:
- If all variables are numeric:
- The used function is
FactoMineR::PCAwith optionsscale.unit = FALSEandncpthat is set to its maximum possible valuemin(ncol(X), nrow(X) - 1).
- The used function is
- Otherwise:
- The used function is
FactoMineR::FAMDwith optionncpset to its maximum possible valuemin(n_num + n_lev, nrow(X) - 1)withn_numthe number of numeric variables andn_levthe total number of levels in the categorical variables minus the number of categorical variables.
- The used function is